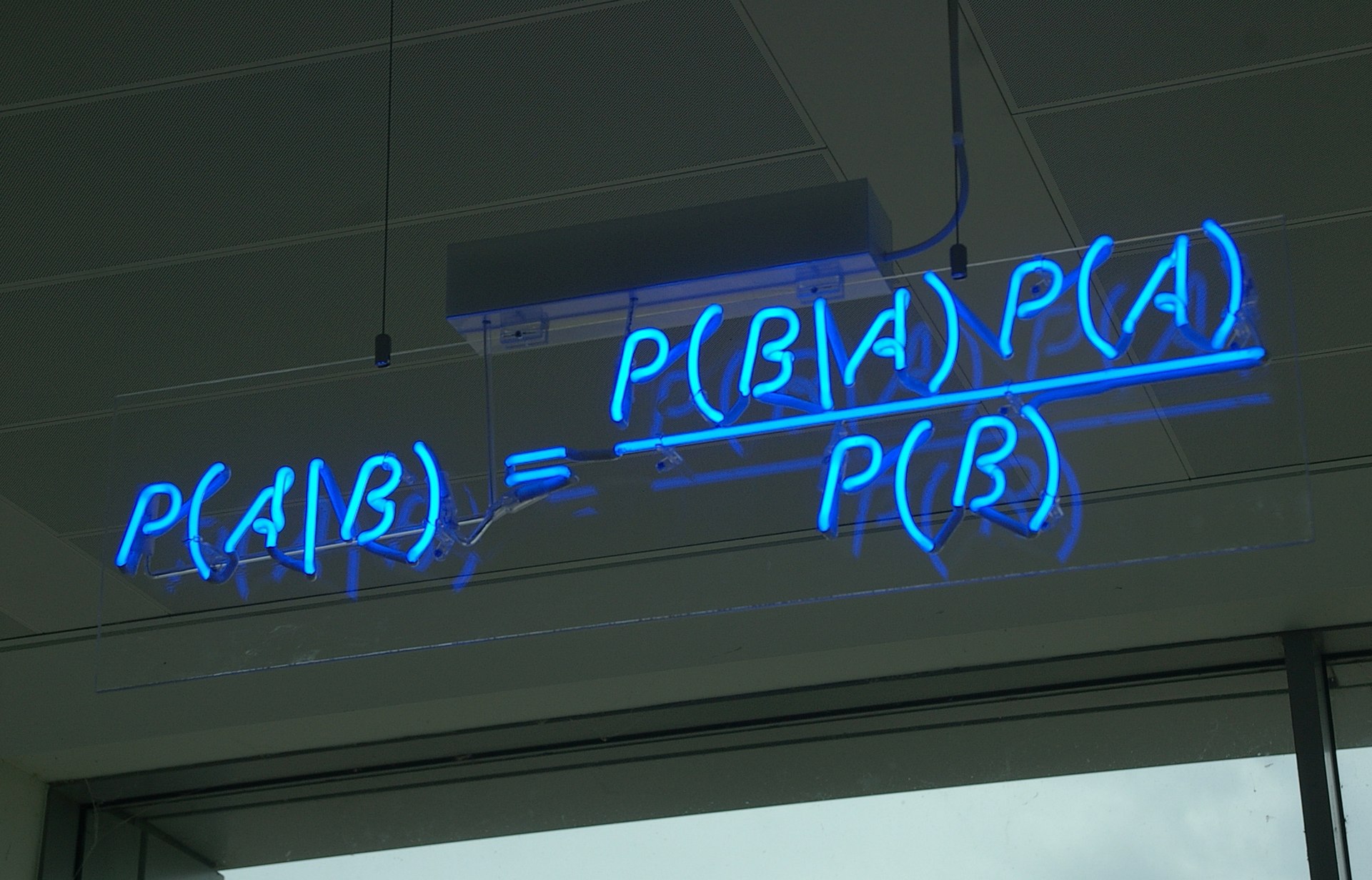
Za tekst odpowiada Miłosz Wieczór, nihilistyczny scjentysta z programem pozytywnym, miłośnik twórczości Prousta.
…ale i czym jest prawda?
Mogłoby się wydawać, że im prostsze pytania zadaje filozof, tym nie tylko trudniej o odpowiedź, ale i tym większa różnorodność odpowiedzi, których udzielić mogliby przechodnie w ramach ulicznej ankiety1. Rzecz skądinąd zupełnie zrozumiała, jeśli posłużymy się wizją świata postulowaną przez językowych strukturalistów: skoro znaczenia słów wynikają tylko z relacji z innymi słowami, to słowa, a w efekcie pojęcia naprawdę fundamentalne („świadomość”, „dobro”, „energia”?), łatwo gubią sens w tysiącach relacji i kontekstów, w których nie tylko pełnią swoją właściwą funkcję, ale i – wobec lenistwa użytkowników języka – zastępują swoje bardziej precyzyjne i specyficzne odpowiedniki. Nietrudno się o tym przekonać, gdy przywołamy różne konteksty, w których „prawdziwy” oznacza zarówno „ściśle zgodny z faktem”, ale i oryginalny, tj. niepodrobiony; „zgodny z moim przekonaniem”, ale i typowy, tj. przystający do schematu; wreszcie sama prawda bywa zarówno synonimiczna z boskością, jak i – prawda? – używana w charakterze całkiem niezobowiązującego przecinka2.
Zadaniem filozofa jest zatem zaprowadzić porządek w dziczy, jaką staje się język oddany na pastwę nie-filozofów3; taki też jest główny cel tego tekstu. Po wtóre, należy jasno i bez sentymentów przedstawić nasze ograniczenia – tak teoretyczne, wynikające z naszej relacji z Naturą i sposobu funkcjonowania języka, jak i praktyczne, będące choćby skutkiem dostosowania poziomu precyzji do wagi zagadnienia. Jeśli esej ten ma posiadać walor dydaktyczny, chciałbym, aby jego tezy rezonowały w Czytelniku w chwilach, gdy coś wyda mu się prawdziwe po prostu, to znaczy: gdy pewna teza sprowokuje u Niego czysto mechaniczną odpowiedź „przecież tak właśnie jest”.
Zacznijmy od zauważenia, że fundamentalnym dla naszego problemu jest rozróżnienie zdań na deskryptywne (pozytywne) i normatywne. Zdania deskryptywne mają za zadanie stwierdzić fakt, podczas gdy zdania normatywne zawierają w sobie element wartościowania: mówią, jak powinno być4. Dla przykładu w zdaniu „jest już po północy, trzeba iść spać” pierwsza część jest ściśle deskryptywna5 – wynika z odczytu wskazania zegara – a druga normatywna, ponieważ nie istnieje obiektywny przymus pójścia spać w tej właśnie chwili, choćby nawet przemawiał za tym rozsądek. Czy to jednak znaczy, że nigdy nie trzeba iść spać?
Otóż głównym problemem zdań normatywnych jest to, że nigdy nie są one prawdziwe same w sobie, tj. do określenia ich prawdziwości nie wystarczy sam zbiór reguł języka, w którym zostały zbudowane. Zdania takie są warunkowane określonym systemem wartości (który notabene często prześwituje przez sposób ich sformułowania), i dopiero po jasnym określeniu aksjomatów tego systemu jesteśmy w stanie przebudować zdanie normatywne w podlegające ocenie logicznej zdanie deskryptywne. Za przykład posłużyć może przeformułowane zdanie „aby utrzymać zdrowie, należy regularnie kłaść się wcześnie„: jest to teza, którą można zweryfikować eksperymentalnie, określając rozmiar efektu, prawdopodobieństwo relacji przyczynowej i znaczenia poszczególnych słów („zdrowie”, „wcześnie”).
Nie do przecenienia dla każdego amatora poszukiwania prawdy jest ćwiczenie polegające na odgadywaniu systemów wartości, w których dane zdanie normatywne okazuje się prawdziwe i fałszywe. O wiele trudniejsza jest jednak często identyfikacja zdań normatywnych, które podszywają się pod deskryptywne. Porównajmy dwie przykładowe konstrukcje: (a) „kontrola granic jest ważna” i (b) „kontrola granic jest ważnym elementem suwerenności„. Mimo dużego podobieństwa składniowego należy odnotować, że zdanie (a) zawiera o wiele większy komponent normatywny – łatwo je przeformułować do postaci „należy X” – podczas gdy zdanie (b) jest w znacznej mierze deskryptywne („aby Y, należy X„). Łatwo dostrzec, że zdanie (a) będzie formułowane tym chętniej, im wyżej w systemie wartości formułującego stała będzie suwerenność.
Aby dodatkowo sprecyzować nasze rozważania, pozwolę sobie na wprowadzenie szeregu oznaczeń, zgodnie z którym:
- p(X) oznaczało będzie funkcję przypisującą zdaniu X wartość od 0 (fałsz) do 1 (prawda), przy czym wartości pośrednie odpowiadają najlepszemu oszacowaniu prawdopodobieństwa, że zdanie X jest prawdziwe;
- L oznacza zbiór współdzielonych w społeczeństwie reguł użytkowania języka (uzus);
- Y oznaczać będzie przyjmowany na potrzeby zdania system wartości;
- D oznacza zbiór parametrów i uszczegółowień służący dookreśleniu ścisłego znaczenia zdania X (np. znaczenie słów „zdrowie” i „wcześnie” w przytoczonym wyżej przykładzie);
- p(X | A) oznacza wartość p(X) pod warunkiem A – np. p(X | L) to p(X) przy przyjęciu reguł językowych L; należy zwrócić uwagę, że samo p(X) nie jest nigdy określone, jeśli nie określimy chociażby języka, w którym zostało sformułowane.
Chcemy zatem powiedzieć, że jeśli X jest zdaniem normatywnym, to wyrażenie p(X | L) nie ma dobrze określonej wartości; w naszym roboczym modelu wartość liczbową posiada dopiero p(X | L, Y), tzn. prawdziwość zdania X w języku L i systemie wartości Y. Gdy i ta wartość okazuje się trudna do zdefiniowania, należy przyjąć zestaw dookreśleń i posługiwać się p(X | L, Y, D).
Istotne w tym miejscu staje się dla nas założenie agnostycyzmu etycznego: skoro usiłujemy w postawie obiektywnej dojść tak daleko, jak to możliwe, nie faworyzujemy z góry żadnego zbioru wartości Y. W przeciwnym wypadku moglibyśmy elementom wyczerpującego zbioru zbiorów wartości {Y} przypisać wagi odpowiadające „rozsądności” danego zestawu aksjomatów, a następnie obliczyć p(X | L) jako średnią ważoną p(X | L, Y) po wszystkich Y. Co to oznacza w praktyce? Nawet jeśli wszystkie czynniki zdroworozsądkowe wskazują na to, że powinienem iść spać6, prawdziwość zdania „po północy trzeba iść spać” pozostaje niezdefiniowana, ponieważ wyróżnienie systemu wysoko wartościującego zdrowie byłoby arbitralne.
Przekorny Czytelnik może w tym miejscu wytknąć mi pewną niespójność. W jaki sposób prawdziwość zdań deskryptywnych może funkcjonować w sposób niezależny od systemu wartości, skoro sam postulat racjonalności stanowi arbitralny wybór systemu wartości opartego o rozum? Innymi słowy – czy jeśli chcę orzekać o prawdziwości zdania „jest po północy”, to nie powinienem wpierw przyjąć, że będę posługiwał się rozsądkiem7? Paradoksu tego możemy uniknąć właśnie dzięki warunkowemu sformułowaniu p(X | L): zdanie X jest prawdziwe w takim sensie, w jakim rozumieją je użytkownicy języka L. Ponieważ pewna forma racjonalności wpisana jest w schemat używania języka, naturalnie przenosi się ona do procesu oceny.
Skoro wyjaśniliśmy sobie, jak przeformułować zdanie normatywne w deskryptywne, zajmijmy się teraz problematyką tych ostatnich. Biorąc pod uwagę jedynie relację czasową, możemy tu wyróżnić cztery rodzaje tez: (a) pozaczasowe (nieempiryczne); (b) historyczne; (c) aktualne; (d) predykcyjne (modele).
Pierwsza kategoria w oczywisty sposób odpowiada temu, co Kant nazywa zdaniami a priori: zdania, których prawdziwość (chociażby w teorii) nie zależy od doświadczenia. Następnie ten słynny mieszkaniec Królewca wprowadza podział na zdania analityczne (wynikające w zupełności z przesłanki – na przykład twierdzenia matematyczne) i syntetyczne (wnoszące dodatkową informację o świecie rzeczywistym – na przykład tezy metafizyczne). Te pierwsze można z łatwością potraktować naszym modelem: zdanie matematyczne może być prawdziwe wyłącznie jako zgodne z przyjętym w matematyce uzusem – chociażby definiującym znaczenie operacji oznaczanej „+”. (Należy tu nadmienić, że pouczeni przez Gödla nie stawiamy wymagania, by każde zdanie dało się rozstrzygająco zakwalifikować jako prawdziwe lub fałszywe.) Te drugie – na potrzeby ilustracji za roboczy przykład przyjmijmy tezę „świat jest wieczny” – sprawiają wiele kłopotu: mimo że wydaje się, iż obiektywnie zdanie takie musi być albo prawdziwe, albo fałszywe, niemal zawsze właściwy problem leży w użyciu nie dość precyzyjnych pojęć; na samym początku ostrzegałem wszak, że pojęcia najbardziej fundamentalne najszybciej rozmywają się, gdy próbujemy uchwycić ich sedno. Dokładnie to dzieje się, gdy usiłujemy słów takich jak „wieczność”, „ideał”, „rozciągłość”, „byt” użyć w ujęciu innym niż poetyckie: nie należy nigdy ufać, że umiemy okiełznać przy ich pomocy coś namacalnego.
Kategoria zdań historycznych (np. „Hitler wiedział o Holokauście”8) stanowi szczególną trudność, ponieważ polega zawsze na dwóch dość silnych założeniach: (q) o ciągłości czasu i (w) o wierności przekazu. Najpierw musimy przyjąć, że przeszłość istniała; alternatywą może być sytuacja, gdzie cały świat – wraz z gotową historią i wspomnieniami mieszkańców – powstał któregoś dnia jak gdyby nigdy nic. Następnie trzeba pogodzić się z tym, że dysponujemy zaledwie „cieniami” faktów: zapiskami w kronikach, relacjami i zapisami relacji, a ich wiarygodność nigdy nie jest pewna. Wobec tego postrzegane subiektywnie wartości p(X | L, q, w) nigdy nie będą równe dokładnie jeden: cały świat teorii spiskowych żeruje właśnie na tym fakcie. Pomocą mogą okazać się – o ile dostępne – potwierdzenia tych samych faktów z niezależnych źródeł albo analizy wiarygodności zastosowanych metod. Można jednak twierdzić, że niezależnie od tego powinna istnieć obiektywna wartość p(X | L, q) – to znaczy, jeśli przeszłość istniała, to dany fakt miał albo nie miał miejsca; i z tak postawioną tezą należałoby się zgodzić: nawet jeśli nie miałaby ona praktycznych implikacji, może nam służyć za wartość graniczną p(X | L, q, w), do której dążymy, pozyskując i ewaluując kolejne źródła.
Mimo że zdania odnoszące się do chwili bieżącej – to znaczy stwierdzające choćby, że widzę stół – wydają się najprostszym przypadkiem z rozważanych w tym tekście, to sam Ludwig Wittgenstein w swym późnym dzienniku-traktacie wymownie zatytułowanym O prawdzie roztrząsa je z wyjątkową szczegółowością. Co bowiem, gdy stwierdzam, że wiem że ten stół jest dębowy, a potem okazuje się, że był to jednak jesion? Jak na sens tego, co mówimy, wpływają formy „wiem”, „jestem przekonany że”, „wydaje mi się”? O ile tego typu rozważania mogą budzić sympatię, przyjęty przez nas model obchodzi całą tę problematykę w zgrabny sposób: czyniąc je częścią definicji uzusu językowego. Dlatego też owszem – jeśli Polak mówi, że widzi stół, pozostaje nam zapisać to jako p(X | L, w), ważąc takie zdanie naszym oszacowaniem wierności przekazu: jeśli w danej chwili jest prawdomówny (a także jeśli nie wydaje mu się jedynie, że widzi stół, ale to obostrzenie powinno być zawarte w samym kryterium wierności), nie mamy podstaw, by wątpić, że jest tak w istocie.
Wreszcie, zdania predykcyjne najłatwiej chyba ująć w formalizm aspirujący do miana naukowego: budowanie modeli, teorii i predykcji to właśnie to, czym naukowcy zajmują się na co dzień9. Ale i czym właściwie jest w tym rozumieniu „model”? Spróbujmy przyjąć definicję możliwie ogólną: jest to pewna struktura konceptualna – najczęściej formułowana w języku matematyki – która pozwala na wnioskowanie o następstwach wybranych zdarzeń10. Co istotne, struktura modeli zazwyczaj umożliwia testowanie ich na danych historycznych i w ten sposób zwykle wnioskujemy o poprawności modelu. Jeśli model Kopernika zgadzał się z obserwacjami astronomów, spełniony był warunek konieczny jego poprawności; łatwo jednak dostrzec, że nie jest to warunek wystarczający, by uznać model za prawdziwy. Dlaczego?
Odpowiedź zależy w znacznej mierze od tego, co próbujemy modelować. Jeśli naszą teorią usiłujemy zająć stanowisko w bardziej uniwersalnym sporze, w którym dowody są pośrednie, o jej uznaniu za prawdziwą będzie najczęściej decydowała prostota (tzw. brzytwa Ockhama: mniej złożone mechanizmy są bardziej prawdopodobne)11. Ale nawet gdy chcemy jedynie uzyskać statystycznie istotną zdolność predykcyjną bez znajomości mechanizmu – powiedzmy, usiłujemy sformułować procedurę diagnozy nowej choroby – sukces odniesiony na już znanych przykładach nie zawsze świadczy o działającym modelu. Jeśli dysponowaliśmy ograniczonym zestawem danych (na przykład dziesiątką pacjentów), nasze predykcje będą nieuchronnie zaburzone przez przypadkowe trendy występujące w tym zestawie danych12.
Tą krótką dygresją wykroczyliśmy jednak nieco poza zakres zdań predykcyjnych. Wróćmy zatem do faktu, że prawdziwość predykcji („jutro będzie padać”) może być oszacowana w oparciu o model (symulowaną na superkomputerach prognozę pogody). Nie zdefiniowaliśmy jeszcze na dobrą sprawę pojęcia prawdziwości modelu. Czy model prawdziwy to taki, który zawsze generuje prawdziwe predykcje?
Korzystając z możliwości, jakie daje ograniczenie się do czystej teorii, możemy spróbować sformalizować prawdziwość modelu, jeśli zdefiniujemy hipotetyczny zbiór wszystkich m wielkości, których wartości może on przewidywać. Jeśli przez πi(g) oznaczymy przewidziane przez model prawdopodobieństwo, że i-ta wielkość przyjmie wartość g, a mierzona za n-tym razem wartość parametru to Gi(n), to niepoprawność modelu możemy zdefiniować jako13:

Oznacza to, że w granicy nieskończenie wielu predykcji prawdopodobieństwa wyników generowane przez idealny model pokryją się ze statystyką rzeczywiście zarejestrowanych zdarzeń; brzmi to (nieprawdaż?) jak rozsądny wymóg.
Niejako za darmo dostajemy tu inny ważny aspekt modelu: kompletność. W kwestiach prawdy ważne jest bowiem nie tylko to, co się mówi, ale również to, czego się nie mówi: od prawdy chcielibyśmy wymagać również, aby przedstawiała kompletny obraz opisywanego zjawiska.
Co jednak, jeśli nasz model jest daleko od optimum? Możliwe, że cała struktura naszego modelu nadaje się na śmietnik: mogliśmy choćby usiłować przewidzieć pogodę na podstawie cen obligacji i aktualnego programu telewizyjnego. Ale jeśli sama struktura modelu ma sens, może winne są nieoptymalne parametry, bo ja wiem, na przykład albedo gleby?
W tym momencie na scenę wchodzi bohater historyczny mniej znany filozofom, Thomas Bayes, wraz ze swoim twierdzeniem zwanym – zgadliście – twierdzeniem Bayesa. Nigdy nieopublikowane przez autora, mówi nam jednak o sprawie najwyższej wagi: jak zmieniać parametry modelu, gdy dysponujemy nagle nowymi danymi. Oznaczmy testowany zbiór parametrów przez D, a zbiór starych i nowych obserwacji jako odpowiednio X i X’; twierdzenie będziemy mogli wówczas zapisać jako14:
p(D | X+X’) ~ p(D | X) · p(X’ | D)
co oznacza: prawdopodobieństwo, że wobec nowych danych poprawny jest zbiór parametrów D, jest proporcjonalne do prawdopodobieństwa, że było ono poprawne wcześniej, razy prawdopodobieństwo, że dane X’ zostałyby wygenerowane gdyby D był poprawnym zbiorem parametrów. Wobec tego wystarczy nam ustalić, który zestaw parametrów faworyzuje nasz nowy zbiór obserwacji – rzecz niemal trywialna, jeśli dysponujemy matematyczną postacią modelu – i wiemy już, jak ulepszyć nasz model!
Pozwólmy sobie przytoczyć przykład. Załóżmy, że podejrzewamy kogoś o szulerstwo: w poprzednich dziesięciu grach w ruletkę dziewięć razy wypadało czarne pole. Możemy spekulować (hipoteza D), że koło jest namagnesowane w taki sposób, że w 90% kulka ląduje na czarnym polu; 0,9 to nasze p(D | X), początkowy „strzał” wynikający ze statystyki. Jeśli za jedenastym razem kulka wyląduje na polu czerwonym, nasz człon p(X’ | D) – odpowiadający na pytanie „jeśli hipoteza D jest prawdziwa, jaka jest szansa, że wypadnie czerwień?” – będzie równy 0,1: po wymnożeniu przez ten czynnik wiarygodność naszej hipotezy mocno „ucierpi”. Gdybyśmy rozważali hipotezę (nazwijmy ją D’), że zwyczajnie mamy pecha, a koło ruletki jest sprawiedliwe, czynnik p(X’ | D’) byłby równy aż 0,5 – po wypadnięciu czerwonego pola alternatywna hipoteza D’ znacznie zyskałaby wobec tego na wiarygodności względem oryginalnej D.
W podobny sposób można ważyć względem siebie dowolny zestaw hipotez, jak długo będziemy pamiętali, że model jest właśnie tym: modelem. Nie zagwarantuję Czytelnikowi, że nawet najbardziej spójna i wszechogarniająca teoria nie jest co najwyżej zbieżnością struktury matematycznej ze stanem faktycznym, nie zaś faktycznym wglądem w naturę Rzeczywistości. Im bardziej oddalamy się zaś od konstruktów matematycznych, tym większe komplikacje wynikające z narzędzi – języka, pośredniczących struktur mentalnych i nośników – i tym większa szansa, że za nasze sądy o tworach prawdopodobnych odpowiada nie chłodna kalkulacja, a sympatie i humory15. Tu jednak nic nie zastąpi przepisu z czasów sokratejskich: dużo się wadzić, często mylić i za każdym razem czerpać stąd nową mądrość. A nade wszystko – znać granice języka i oddzielać normy od faktów.
Przypisy
1https://www.youtube.com/watch?v=i3OACvmEgOw
2Niektórych pragmatystów rozbieżności te skłaniają do odrzucenia pojęcia prawdy i zastąpienia je koncepcją użyteczności (poznawczej? społecznej?); nawet jeśli radykalny, pomysł ten nie jest zupełnie pozbawiony sensu.
3Politycy, patrzymy na was.
4Tu znów można wejść w polemikę z filozofami podkreślającymi, że nawet pozornie oczywiste fakty są zawsze zapośredniczone przez – arbitralne z natury – struktury i mitologie budujące nasz aparat poznawczy.
5Niezależnie od prawdziwości i sensowności w sensie ścisłym: zawsze jest po poprzedniej i przed najbliższą północą, jednak uzus językowy wyrażeniu „po północy” przypisuje znaczenie „czas między 0:00 a bliżej nieokreślonym porankiem”.
6Co wydaje się być prawdą – jest przeszło druga w nocy.
7Za utożsamienie rozumu z rozsądkiem wrażliwych Czytelników pragnę przeprosić.
8Najprawdopodobniej wiedział, ale jeśli nieufny Czytelnik zechce ocenić sam… https://histmag.org/Czy-Hitler-nie-wiedzial-o-Holokauscie-Wersja-tldr-skrocona-9554
9Jeśli akurat nie wpadli w spiralę poleceń na YT.
10By pozostać w duchu filozofii nauki, trzeba tu podkreślić, że proces naukowy produkuje dokładnie to – modele, czyli pomocnicze struktury matematyczne. Nauka modeluje świat; jeśli przy tym odkrywa fundamentalne prawdy, to niejako przy okazji.
11Ponieważ w świecie nie wszystkie procesy zachodzą w najprostszy wyobrażalny sposób, możemy wyobrazić sobie, jak często użycie brzytwy Ockhama sprowadza nas na manowce; czy jednak mamy dobrą alternatywę?
12W świecie uczenia maszynowego problem ten nazywa się problemem nadmiernego dopasowania, a dotknięty nim model – modelem o dużej wariancji
13W podobny sposób można sobie wyobrazić, jak najbardziej zbliżyć się do kantowskiej rzeczy samej w sobie (noumenu): stworzyć model, który we wszystkich hipotetycznych układach eksperymentalnych produkuje dokładnie te same fenomeny (obserwacje), co prawdziwy obiekt. Fizycy często utożsamiają taki model z właściwym obiektem, który próbują opisać, i przyznać trzeba, że nie popełniają przez to aż takiego błędu; pozostaje jednak pytanie, czy i sam noumen – „rzecz czysta”, niezależna od zmysłów i obserwacji – posiada strukturę matematyczną. Ciekawą namiastką noumenu jest w mechanice kwantowej funkcja falowa: sama pozostaje niemożliwa do zaobserwowania, ale dyktuje wszystkie właściwości układu.
14Czytelnika proszę, by docenił podniosłość chwili.
15Warto zwrócić uwagę na błysk geniuszu zawartego w etymologii: „humory” to dawniej też płyny ustrojowe oddziałujące na nasz odbiór świata, a więc m.in. hormony.
Miłosz Wieczór (ur. 1991) – Nihilistyczny scjentysta z programem pozytywnym. Od czasu lektury Prousta uważa, że życie „jest spoko”, o co zresztą nieustannie kłóci się sam ze sobą. Aktualnie mieszka i pracuje w Barcelonie, gdzie poza modelowaniem układów biologicznych uczy się odróżniać kastylijski od katalońskiego.